① [AGI를 바라보는 세계관] 위험 감수가 불가피한 인류의 목적지 vs. 위험한 미지의 영역
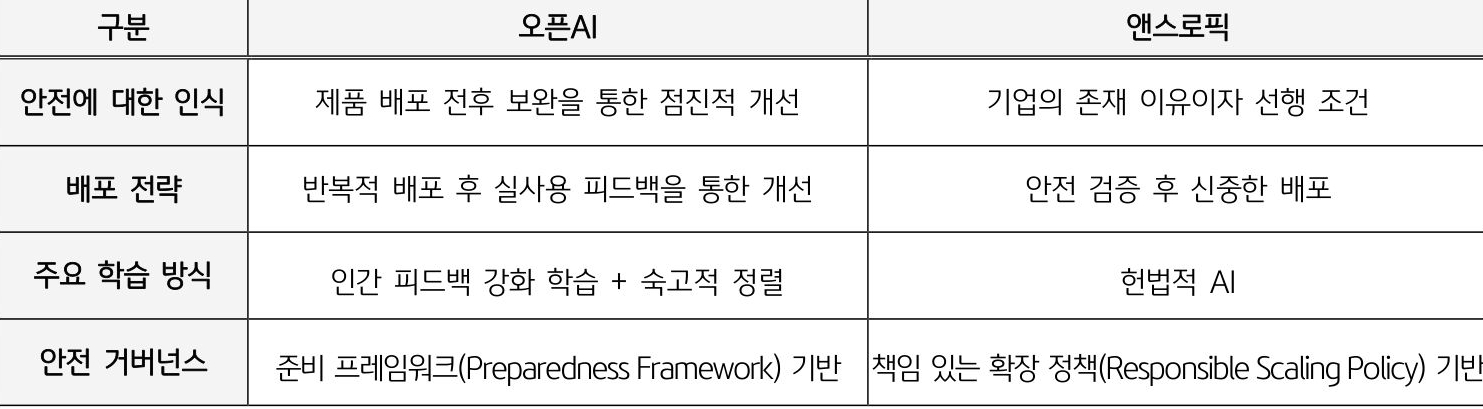
○ (오픈AI) AGI는 인류가 빠르게 도달해야 할 목적지로, 신속하고 반복적인 배포로 실제 환경의 피드백을 수렵하고 이를 바탕으로 모델을 개선해 나가는 전략을 채택
- “수익 없이는 AGI 개발도 불가하다”는 논리를 앞세워, 상업화와 신속한 배포를 단순한 수익 창출을 넘어 사명 달성을 위한 필수 수단으로 정당화. 상업화를 통해 창출된 수익은 안전 연구와 인프라에 재투자해 선순환을 유도
- 올트먼은 AGI 도달 과정에서 발생하는 모든 위험을 사전 예측하는 것은 불가능하며, 빠르고 반복적인 배포를 통해 실제 환경에서 발생하는 위험을 지속적으로 개선해 나가야 한다는 입장